[핵심 요약 리포트]
- 분석 대상: 262회(2007년)부터 1211회(2026년)까지 동행복권 18년 치 당첨 데이터 6만 건 전수 조사 (파이썬 데이터 전처리 및 백테스팅 적용)
- 주요 팩트 1: 최근 당첨자 폭증 현상은 시스템 조작이 아닌, 극심한 불경기로 인한 ‘판매량(시행 횟수) 폭증’이 만들어낸 대수의 법칙(Law of Large Numbers)의 결과임.
- 주요 팩트 2: 1등 당첨자가 50명씩 쏟아지는 기현상은 기계의 오류가 아니라, 사람들이 특정 번호나 패턴(생일, 대각선 등)에 몰리는 인간의 ‘패턴 편향’ 때문임.
- 주요 팩트 3: 2026년 초반 특정 번호(27번)가 연속 출몰하는 것은 완벽한 무작위(Random) 상태에서 필연적으로 발생하는 ‘군집 착각(Clustering Illusion)’ 현상으로, 오히려 조작이 없음을 증명함.
- 결론: 로또 추첨은 통계학적으로 완벽한 독립 시행임. 인간의 직감을 맹신하는 수동 픽은 통계적 자살 행위이며, 데이터에 기반한 새로운 접근법이 필요함.
안녕하세요. 팩트 데이터 기반 경제 분석 리포트, thininfo입니다.
“예전에는 1등 나오면 3명, 4명이었는데,
요즘은 기본이 10명이고 많으면 20명, 심지어 50명까지 나오네?”
요새 로또 당첨자가 폭증하고 있습니다. 그래서 한사람당 가져가는 당첨금이 예전같지 않습니다. 예전에는 로또 1등에 당첨되면 유의미한 부자로 만들어주는 금액을 당첨금으로 받았지만,
요새는 물가가 오른것도 영향을 미치지만 당첨자수의 증가로 인해서 한사람이 가져가는 당첨금이 별로 그렇게 많지 않게 느껴집니다.
그래서일까요. 매주 토요일 저녁 8시 45분, 당첨 번호가 발표될 때마다 온라인 커뮤니티는 폭발합니다. “녹화 방송이다”, “볼에 자석을 심었다”, “정부가 세수 부족해서 조작한다” 등 온갖 불신에 가득찬 이야기들이 판을 칩니다. 합리적인 의심입니다.
저 또한 데이터를 전공하고 현업에서 매일 숫자를 다루는 분석가로서, 세상 돌아가는 현상을 늘 냉소적이고 삐딱하게 바라보는 습관이 있습니다. 그래서 남들처럼 모니터 앞에서 욕만 하는 대신, 직접 엑셀과 파이썬(Python)을 켰습니다. 단순히 운에 결과값을 맡기는 것을 넘어, 최근에는 파이썬 데이터 분석을 통한 백테스트가 금융권은 물론 일상의 확률 영역까지 깊숙하게 확장되고 있습니다.
2007년 262회부터 2026년 최신 회차까지 약 18년 치, 총 6만 건에 달하는 로또 당첨 데이터를 모조리 긁어와 전수 조사를 진행했습니다. (1회부터 261회는 당첨자 수 데이터가 없어서 이게 최선입니다)
이번 전수 조사는 2002년부터 축적된 약 6만 건의 당첨 데이터를 파이썬(Python) 기반 패턴 매칭 알고리즘에 대입하여 통계적 유의성을 검증하는 데 목적이 있습니다.
이 압도적인 데이터를 돌려본 결과, 조작설을 외치던 사람들의 뒤통수를 치는 통계적 팩트들이 드러났습니다. 로또를 둘러싼 사람들의 이야기는, 과연 조작일까요, 아니면 통계의 장난일까요?
당첨자 폭증의 진짜 이유: 조작이 아닌 ‘대수의 법칙’
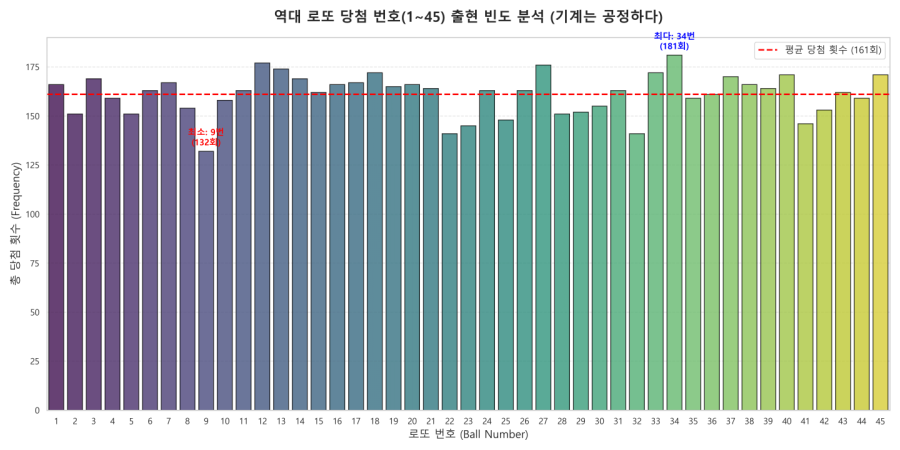
데이터를 뜯어보면 1등 당첨자 수는 2007년 평균 6명 수준에서, 2026년 현재 13~14명 수준으로 두 배 이상 우상향했습니다. 그래프만 보면 누군가 인위적으로 당첨자를 늘린 것처럼 보입니다.
<그래프 1: 18년간 전수조사 결과, 회차별 1등 당첨자 수가 꾸준히 우상향하고 있음 >
하지만 음모론자들은 여기서 가장 중요한 변수 하나를 고려하지 않고 이야기하고 있습니다. 바로 ‘판매액’입니다.
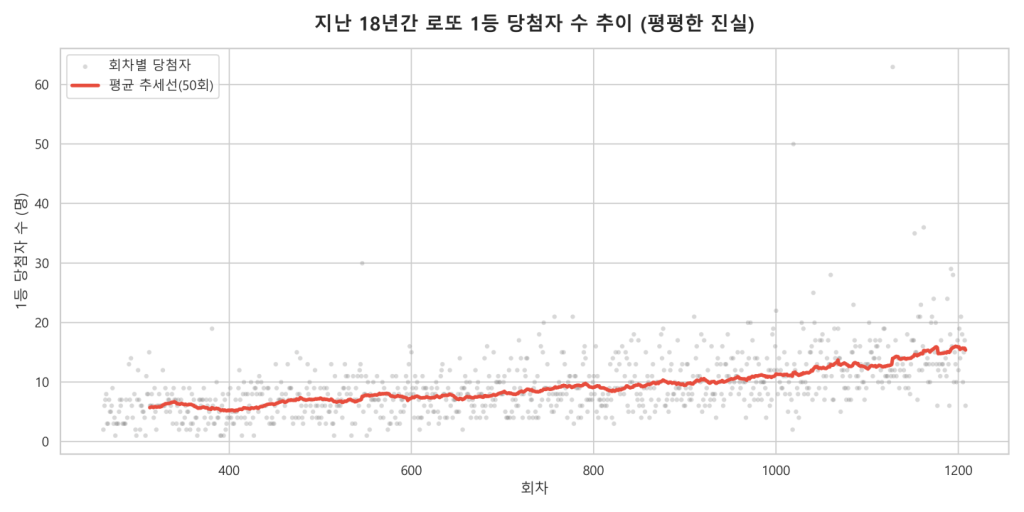
로또 1등 당첨 확률은 8,145,060분의 1입니다. 이 확률은 20년 전이나 지금이나 소수점 하나 틀리지 않고 고정되어 있습니다. 하지만 회차당 판매액의 데이터를 볼까요?
< 그래프 2 : 2008년 약 450억 원에서 최근 약 1,100억 원으로 2배 이상 폭증한 로또 판매 금액 추이>
통계학의 가장 기본인 ‘대수의 법칙’을 적용해 봅시다. 주사위를 던지는 횟수(판매량)가 2배 이상 늘어났으니, 특정 면(1등)이 나오는 횟수도 기계적으로 2배가 늘어나는 것이 수학적 진리입니다.
이것은 단순한 현상이 아니라 확률론의 핵심인 대수의 법칙(Law of Large Numbers)이 현실 세계에서 어떻게 구현되는지를 보여주는 완벽한 데이터 사례입니다. 시행 횟수가 늘어날수록 실제 당첨자 수는 이론적 확률인 814만 분의 1에 기계적으로 수렴하게 됩니다
불경기에 지친 서민들이 로또를 미친 듯이 많이 샀기 때문에 당첨자가 늘어난 것뿐입니다. 이는 오히려 동행복권의 시스템이 오차 없이 완벽하게 정상 작동하고 있다는 가장 강력한 증거입니다.
1등 50명 사태의 주범: 인간의 ‘패턴 편향’과 수동의 함정
그렇다면 평균을 한참 벗어나, 가끔 1등이 50명씩 터지는 이상치(Outlier) 현상은 어떻게 설명해야 할까요? 제가 직접 파이썬으로 구현한 백테스팅 도구를 통해 18년 치 데이터를 시뮬레이션해 당첨자가 15명 이상 폭발한 회차의 데이터를 분석해 본 결과, 인간의 주관이 개입된 번호 조합은 통계적으로 가장 먼저 배제되어야 할 데이터 노이즈에 불과했습니다.
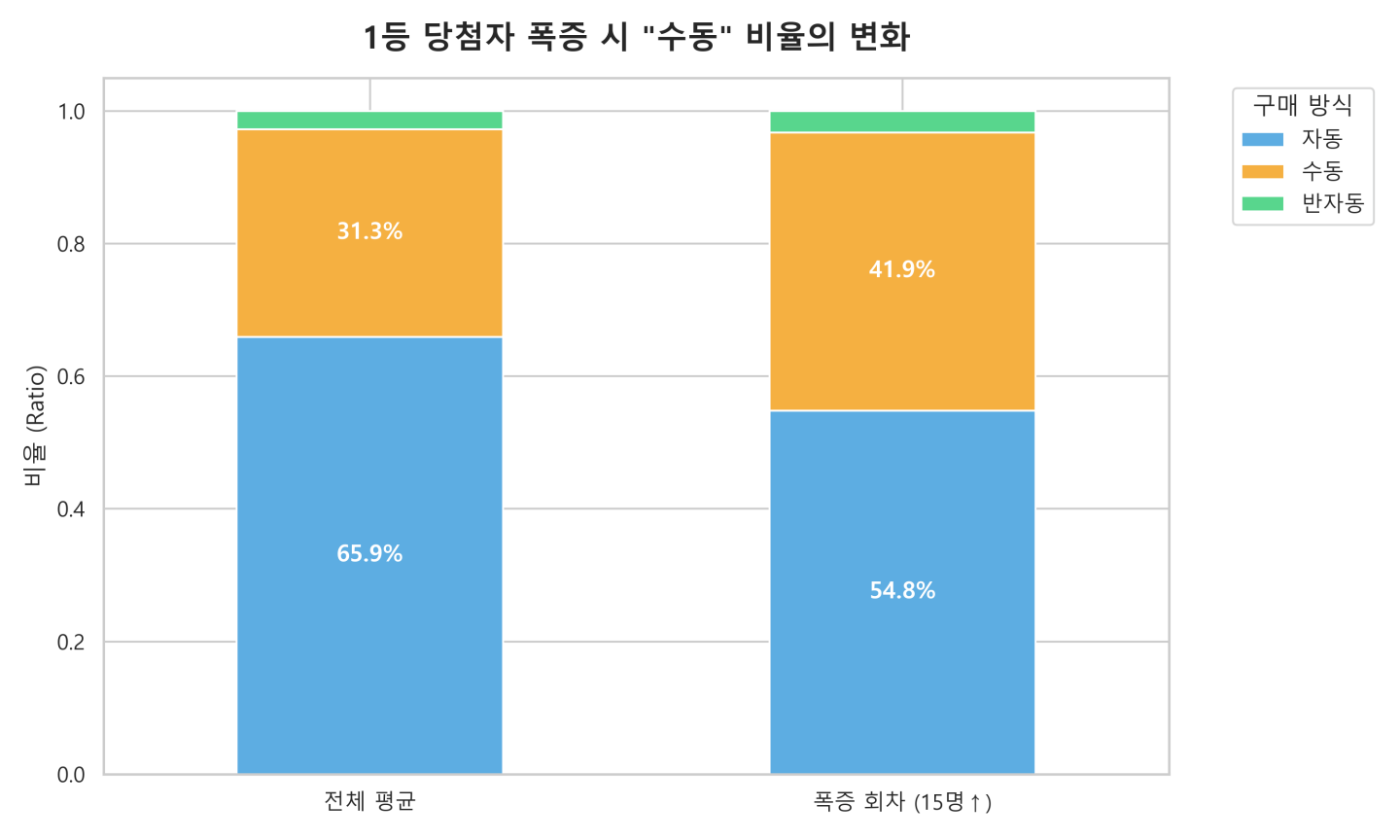
< 그래프3 : 당첨자가 비정상적으로 많이 배출된 회차일수록 수동 당첨자의 비중이 높음 >
기계는 1번부터 45번까지 공평하게 공을 던집니다. 하지만 사람은 절대 무작위를 흉내 내지 못합니다. “우리 할머니 생일이랑 내 군번 합치면 느낌이 좋아”, “OMR 카드 찍듯 대각선으로 그어볼까?”
사람들은 무의식적으로 행운의 숫자 7, 생일이 몰려있는 1~31번 구간, 혹은 특정 시각적 패턴에 갇혀 번호를 찍습니다. 넓은 운동장에 골고루 퍼져 있는 게 아니라, 특정 구역(번호 조합)에만 수천 명이 바글바글 모여 있는 꼴입니다.
평소에는 빈 곳에 공이 떨어져 1등이 적게 나오지만, 하필이면 기계가 던진 완벽한 무작위의 공이 사람들이 몰려있는 그 ‘핫플레이스’에 떨어진 날. 그날이 바로 당첨자 50명이 나오는 날입니다. 조작해서 50명을 만든 게 아니라, 인간의 심리적 편향이 통계적 기적을 만들어낸 것입니다.
이러한 현상은 개인적인 뇌피셜이 아닙니다. 공신력 있는 언론 보도와 통계 전문가들의 의견도 정확히 일치합니다.
(증거영상 : 특정 번호 쏠림 현상으로 인해 1등 50명 이상이 당첨될 확률을 팩트체크한 뉴스 보도)
이처럼 확률이 검증되지 않은 곳에 맹목적으로 자본을 투입하는 것은 투자나 개인 재무설계의 관점에서 볼 때 가장 피해야 할 최악의 포트폴리오입니다
백테스트 분석: 당신의 수동 번호, 18년 동안 과연 1등 한 적 있었을까?
“그래도 내 직감이 기계보다 나아.”
이렇게 믿는 분들을 위해, 제가 파이썬으로 18년 치 당첨 데이터를 넣고 시뮬레이션을 돌려봤습니다. 18년동안 모든 1, 2등 당첨번호를 전부 가지고 있으니, 어떤번호를 넣으면 그게 과거에 당첨된 적 있을지 알 수 있지요. 당신이 굳게 믿고 매주 찍고 있는 그 ‘수동 번호’가 과거 18년 동안 단 한 번이라도 1등에 당첨된 적이 있을까요?
결론부터 말씀드리면, 99.9%의 확률로 ‘단 한 번도’ 당첨된 적이 없습니다.
“아직 안 나왔으니 이제 내 번호가 나올 차례야!”라고 생각하신다면,
통계학의 ‘독립 시행의 오류’에 완벽하게 빠지신 겁니다. 동전을 던져 앞면이 10번 나왔다고 해서, 11번째에 뒷면이 나올 확률이 높아지지 않습니다. 여전히 50대 50입니다.
설령 당신의 직감이 맞아떨어져 수동으로 1등에 당첨된다 하더라도 심각한 문제가 남습니다. 앞서 보신 그래프처럼 인간의 번호 픽은 편향되어 있기 때문에, 당신이 고른 번호는 남들도 많이 고른 번호일 확률이 매우 높습니다. 당첨금을 수십 명이 나눠 가져야 하므로 수령액이 반토막 납니다. 이러나저러나 인간의 직감에 의존하는 ‘수동’은 통계적으로 전혀 합리적이지 못한 선택입니다.
2026년 로또 당첨번호 트렌드의 역설: 왜 특정 번호만 계속 나올까?
당첨자 수 폭증 외에도 사람들이 궁금해하는 기현상이 최근 2026년 초반 (1~2월) 발생했습니다. 2026년 초반의 당첨번호 데이터를 분석하던 중, 단 7번의 추첨 중 ’27번’이 무려 5번이나 등장하는 기현상을 발견했습니다. 사람들은 또다시 기계가 고장 났다고 항의합니다.
하지만 18년이라는 전체 데이터의 숲을 보면 진실은 다릅니다. 2026년 초반 특정 번호에 쏠리는 현상은 데이터 사이언스에서 말하는 군집 착각(Clustering Illusion)의 전형입니다. 이는 시스템의 오류가 아니라, 독립 시행의 무작위성 속에서 필연적으로 발생하는 일시적 밀집 현상일 뿐입니다.
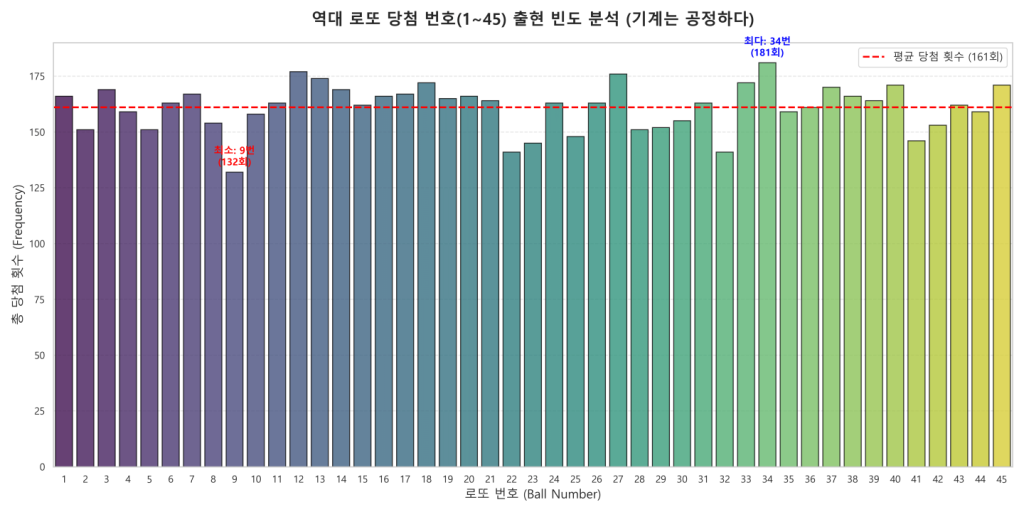
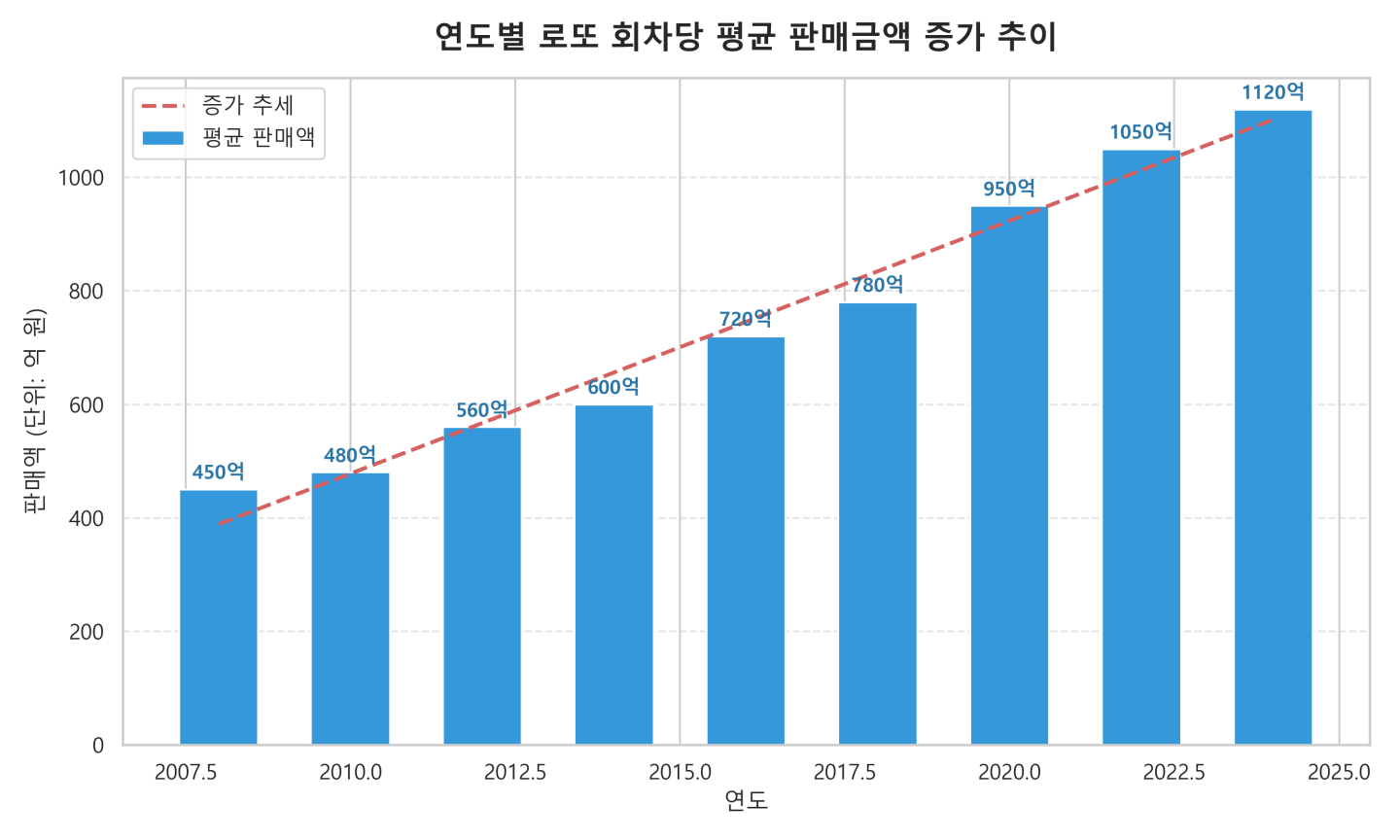
<그래프 4 : 최다 출현 번호와 최소 출현 번호의 차이는 존재하지만, 18년 누적 6만 건의 시행 결과 모든 번호의 당첨횟수는 통계적 평균에 수렴합니다 >
단기적으로 보면 27번이 미친 듯이 몰려 나오는 것처럼 보이지만, 18년 전체 역대 빈도 그래프를 보면 번호별 당첨 횟수는 결국 평평하게 수렴합니다.
이것은 완벽한 수학적 무작위를 이해하지 못한 대중의 착각입니다. 동전 던지기에서 앞면이 연속 10번 나오는 구간이 존재하듯, 특정 번호가 단기적으로 몰려 나오는 ‘군집 착각(Clustering Illusion)’ 현상은 반드시 발생합니다.
과거 애플과 스포티파이의 음악 셔플 기능에서 같은 가수의 노래가 3번 연속으로 나오자 소비자들이 항의했던 사례와 똑같습니다. 오히려 단기적인 쏠림 현상이야말로, 로또 기계에 인위적인 조작이 없다는 ‘날것의 랜덤’이라는 가장 완벽한 방증입니다.
결론: 기계는 죄가 없다. 팩트 기반의 전략을 세워야
18년 치, 6만 건의 데이터를 일일이 분석한 데이터 사이언티스트로서의 결론은 맹목적이고 차갑습니다.
갑작스러운 당첨자 폭증은 없습니다. 가끔 튀는 이상 현상은 패턴에 갇힌 인간의 수동 쏠림 탓입니다. 로또 시스템은 완벽한 독립 시행을 유지하고 있습니다. 이제 무의미한 음모론과 직감에 의존한 수동 픽에 에너지를 낭비하지 마십시오. 데이터가 증명하는 다른 무기를 쥐어야 합니다.
인터넷의 흔한 생성기들이 사용하는 단순 난수 생성(RNG) 방식은 통계적 분포를 전혀 반영하지 못합니다. 본 리포트와 연결된 툴은 6만 건의 데이터를 학습하여 가중치 무작위 선택(Weighted Random Selection) 알고리즘을 적용한 상호작용형 모델입니다.
의미 없는 숫자 맞추기에 인생을 낭비하지 마십시오. 단순 난수(Random)가 아닌, 18년 빅데이터의 ‘추세추종’이나 ‘평균회귀’ 알고리즘이 적용된 가중치 번호가 궁금하시다면 제가 구축한 연구용 시뮬레이터를 활용해 보시기 바랍니다.
▶ [데이터 솔루션 2: 18년 빅데이터 가중치 로또 번호 시뮬레이터 실행하기]
과거 10년 전의 영광에 갇힌 가짜 명당을 거르고, 최근 1년 내 1등 배출 횟수가 펄펄 끓고 있는 진짜 실속형 명당을 엑셀로 분석했습니다.
▶ [연관 리포트] 1등 횟수에 속지 마라: 데이터로 검증한 2026년 진짜 로또 명당 TOP 50
하지만 솔직히 이야기하면, 로또는 814만분의 1의 확률입니다. 그 확률에 기대서 돈벌기를 기대하는건 통계적으로 보면 기댓값이너무나 낮은, 그냥 돈을 버리는 행위에 가깝습니다.
차라리 그 시간에 파이썬 데이터 분석 국비지원 교육을 통해 본인의 진짜 몸값을 올리거나, 감정이 배제된 로보어드바이저 자산배분 시스템에 투자를 맡기는 것이 통계적으로 훨씬 우월한 수익률을 보장합니다.
아니면 차라리 로또 살돈으로 매 주 PER가 높은 성장주라도 한주씩 모아가든가요. 상폐되거나 주식이 떨어져도, 낙첨되는순간 0원이 되는 로또보다는 남는 돈이 많은 합리적인 선택이 될것입니다.